Logistic Classification - 이진 분류의 핵심 원리
머신러닝에서 가장 많이 쓰이는 문제 유형 중 하나가 "둘 중 하나를 고르는" 이진 분류(binary classification)다. 스팸 메일 필터, 사기 거래 탐지, 질병 진단 등 실무에서 마주치는 많은 문제가 이 유형에 속한다. 이 글에서는 이진 분류의 기본이 되는 Logistic Classification을 정리한다.
Logistic Classification
Logistic Classification이란 무엇인가
Logistic classification이란 학습을 통해 특정 상황에 대한 선택지(예/아니오)를 고르는 것이다. 이 중에서 true or false 중 하나를 고르는 것을 binary classification 이라고 하는데, 본 글에서는 이러한 binary classification을 기준으로 학습한다. 이러한 binary classification의 활용범위는 매우 넓은데, 가령 수신함의 메일이 스팸인지 아닌지를 구분한다던가, 페이스북과 같은 SNS 매체에서 특정 사용자의 타임라인에 어떤 게시물을 show 할것인지 혹은 hide 할 것인지를 결정하는 것은 이러한 binary classification을 활용한 것이라 할 수 있다.
이러한 binary classification의 활용도는 점차 높아지고 있으며, 신용카드 사기 거래 탐지, 주식 매입/매도 결정, 의료 진단 등 다양한 분야에서 활용된다.
개인적인 생각: 실무에서 logistic classification을 처음 적용해본 건 사용자 이탈 예측이었다. "이 사용자가 다음 달에 서비스를 해지할 것인가?"라는 질문을 이진 분류로 풀었다. 정확도가 완벽하지 않더라도, "이탈 위험이 높은 사용자"를 미리 파악해서 리텐션 캠페인을 돌릴 수 있었다. 비즈니스 임팩트가 확실한 분야다.
Linear Regression으로는 왜 안 될까?
Linear regression 모델에서는 어떤 입력값의 정도에 따라 출력값을 정도가 변화하는 일종의 선형적인 관계를 나타내는 반면 이러한 의사결정 모델에서는 특정 임계치를 넘기는 순간 결과는 true로 그 정도가 달라지지 않기 때문에 linear regression 모델을 사용할 경우 많은 오차가 발생할 확률이 높아지게 된다.
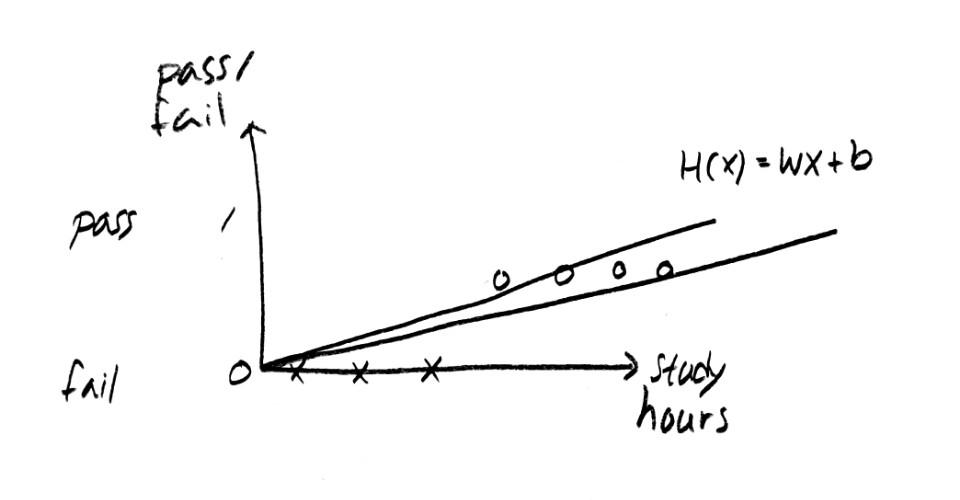
아래 그림은 linear regression을 이러한 classification에 활용하였을 때 나타날 수 있는 문제를 보여준다. 아래 그림과 같이 다양한 사례들을 통해 학습을 지속하면 어떤 임계치보다 상당히 큰 값이 입력으로 들어갈 경우 weight에 큰 영향을 주기 때문에 적당한 W 값을 찾는데에 큰 어려움이 발생하게 된다. 가령 공부를 5시간만 해도 시험에 합격할 수 있는데, 어떤 학생이 공부를 100시간을 하고서 시험에 합격한 사례가 있을 경우 합격에 필요한 시험의 절대적인 공부시간이 실제보다 상당히 크게 예상할 수 있는 상황이 나타난다.
logistic classification의 cost function
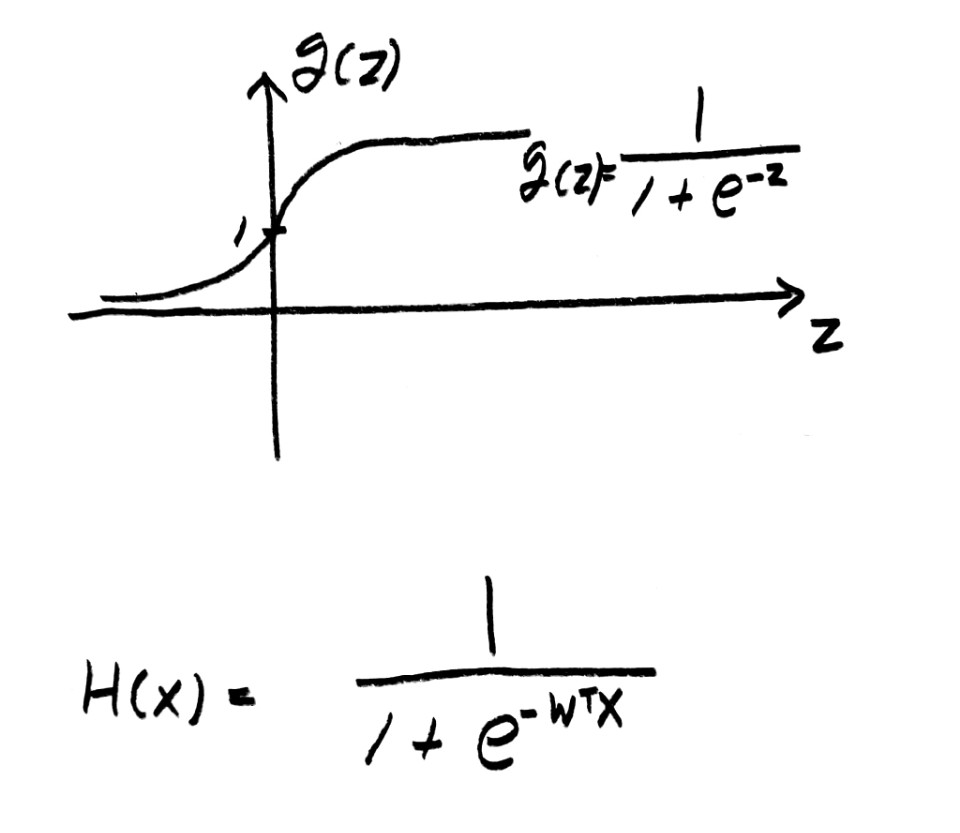
linear regression과 마찬가지로 logistic classification의 경우에도 적합한 hypothesis가 필요해졌다. 앞에서 설명한 바와 같이 linear regression에 도입된 hypothesis의 경우에 도입된 수식이 아닌 0~1 사이에서 좁게 움직일 수 있는 새로운 hypothesis를 위해 새로운 function이 필요하게 되었고, 이에 가장 적합한 sigmoid 함수로 이를 표현하기로 했다. sigmoid 함수의 경우 0을 기준으로 기울기가 급변하기 때문에 이러한 classification의 표현에 아주 적합한 모델이다.
아래는 sigmoid함수와 logistic classification에서의 hypothesis function 을 나타낸다.
logistic classification에서의 hypothesis를 도출하기 위한 과정은 다음과 같다
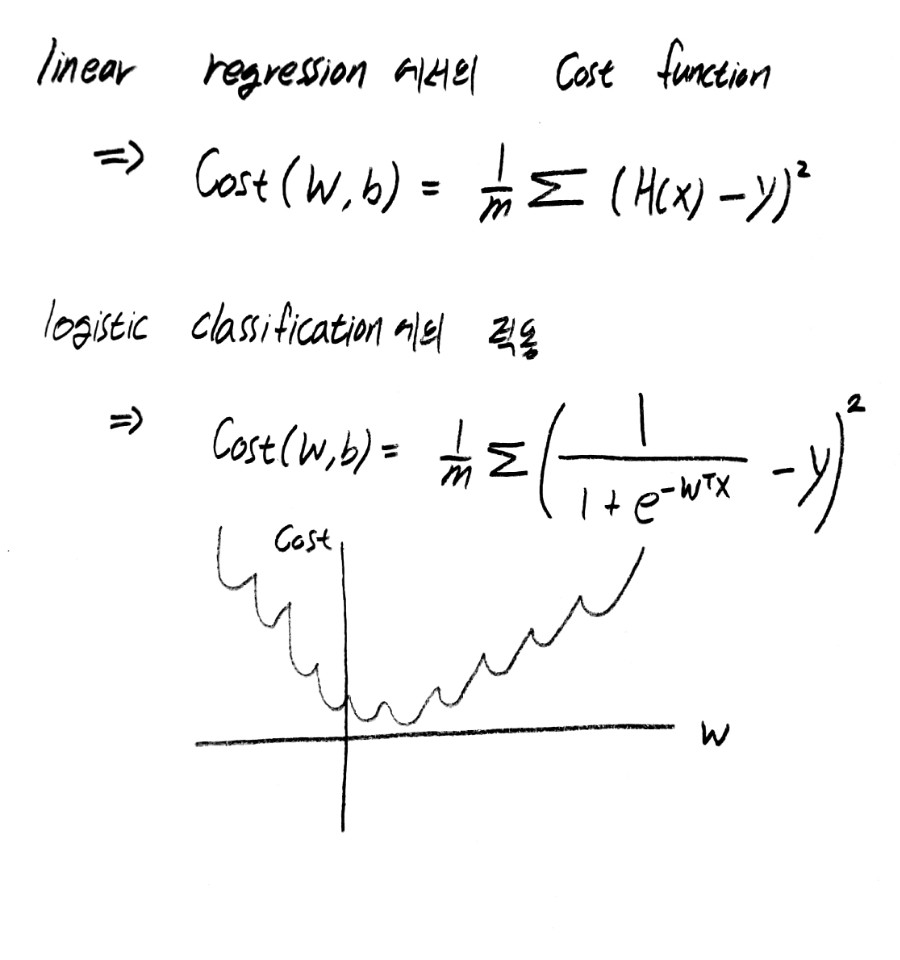
이러한 sigmoid 기반의 hyphthesis의 cost를 구할 때에 기존처럼 차의 제곱을 도입하면 다음과 같은 문제가 생기게 된다. sigmoid의 exponential 부분에 의해 다음과 같이 그래프가 출러이게 되고, 각 부분마다 local minimum 값이 나오게 되어 gradient descent algorithm을 적용하면 cost의 최소값이 어디부터 시작하느냐에 따라 전체 함수의 최소값은 global minimum값이 아니라 local minimum으로 수렴할 가능성이 높아진다. 아래 그림은 차의 제곱을 기반으로 한 linear regression 에서의 cost function 모델의 도입했을 때의 그래프 이다.
따라서 cost 함수도 바뀌어야 할 필요가 생기게 되었고 다음과 같은 새로운 cost function이 제시되었다.
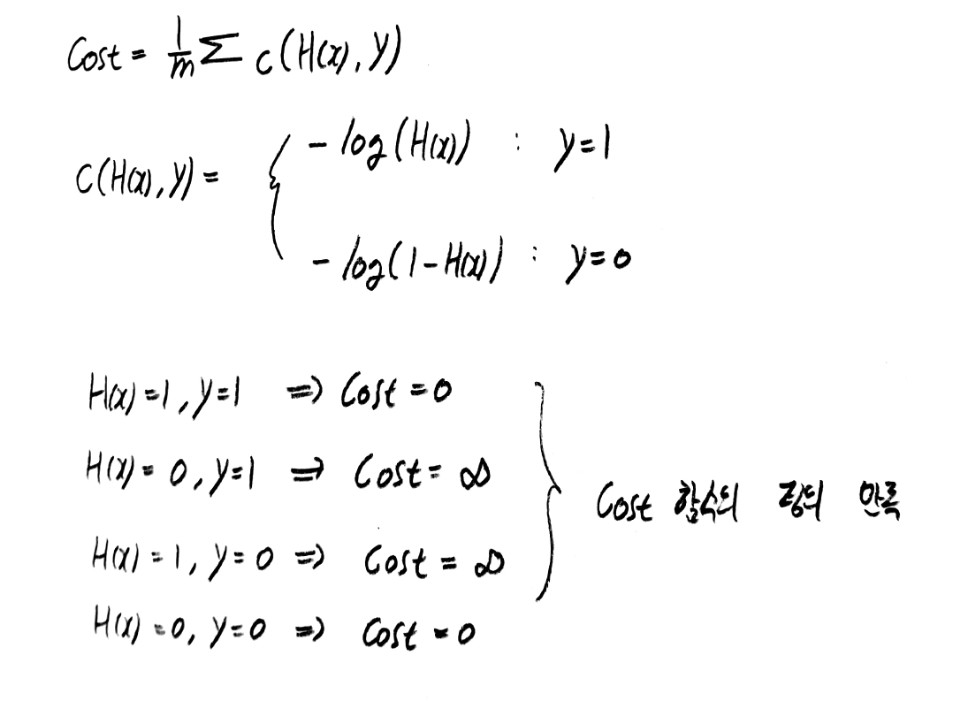
이러한 새로운 cost function에서는 local minimum은 존재하지 않고 global minimum 값만 있기 때문에 gradient descent algorithm을 적용할 수 있게 된다. 하지만 위와 같은 식에서는 python으로 코드를 만들 때 if 문을 계속해서 돌려줘야 하기 때문에 다음과 같은 식으로 변형한다.
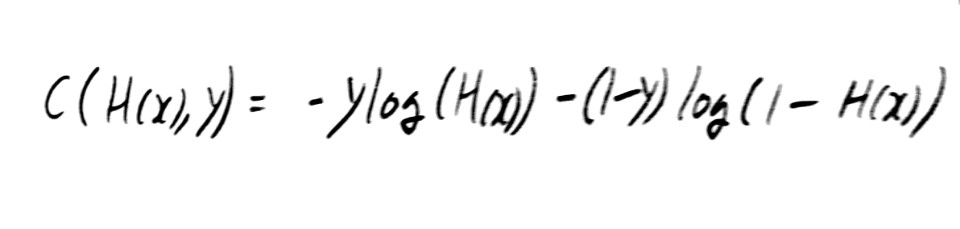
마무리
Logistic classification의 핵심 포인트를 정리하면:
- 왜 sigmoid? - 출력을 0~1 사이로 제한해서 확률처럼 해석할 수 있다.
- 왜 cost function을 바꿔야 하나? - 기존의 MSE(Mean Squared Error)를 쓰면 local minimum이 여러 개 생겨서 gradient descent가 제대로 작동하지 않는다.
- cross-entropy loss - log를 이용한 새로운 cost function은 convex(볼록) 형태라서 global minimum을 찾을 수 있다.
개인적인 생각: 처음 배울 때 "왜 굳이 cost function을 저렇게 복잡하게 바꾸나?"가 이해가 안 됐다. 하지만 실제로 그래프를 그려보면, sigmoid에 MSE를 쓰면 정말 울퉁불퉁해서 최적화가 안 된다. 수학적 직관보다는 "이렇게 안 하면 학습이 안 된다"는 실용적 이유가 더 크다.