B-트리 - 데이터베이스 인덱스의 핵심 자료구조
데이터베이스 인덱스가 어떻게 동작하는지 궁금했던 적이 있다면, B-트리를 이해해야 한다. MySQL, PostgreSQL 등 대부분의 관계형 데이터베이스가 인덱스 구조로 B-트리(또는 그 변형인 B+트리)를 사용한다. 이 글에서는 B-트리의 개념과 동작 원리를 정리한다.
m-원 탐색트리란 무엇인가?
B-트리를 배우기 전에 그 근본 개념이 되는 m-원 탐색트리에 대해 알아보자. 기존의 이진 탐색트리 에서 균형 이진 탐색트리인 AVL 트리의 경우 n 개의 노드에 대해서 깊이가 최소 logn에 가깝기 때문에, 실제 시스템에서 AVL 구조로 저장된 데이터에 접근하기 위해서는 만약 모든 노드가 다른 메모리 안에 들어 있다면 최악의 경우 logn번 만큼 메모리 혹은 디스크에 접근을 해야 했습니다.
이렇게 수 차례에 걸쳐 메모리 혹은 디스크에 접근하는 것은 치명적인 탐색 시간 상승을 야기했다. 이에 탐색 트리의 높이를 줄여 탐색시간을 줄이기 위한 많은 노력들이 있었고, 이를 위해서는 필수적으로 트리의 차수가 증가 해야 했다.
m-원 탐색트리는 m개의 차수를 가지는 노드들로 구성된 트리이며, 실제로는 트리 노드들이 하나의 캐시 블록이나 디스크 블록을 채울 수 있는 가장 큰 차수를 사용한다.
개인적인 생각: 여기서 핵심은 "디스크 접근 횟수를 줄인다"는 점이다. 메모리 접근은 나노초 단위지만, 디스크 접근은 밀리초 단위다. 수만 배 차이가 난다. 그래서 데이터베이스에서는 트리 높이를 낮춰서 디스크 I/O 횟수를 최소화하는 게 성능의 핵심이다.
m-원 탐색트리의 정의는 다음과 같습니다.
m-원 탐색트리의 정의

m-원 탐색트리의 예시
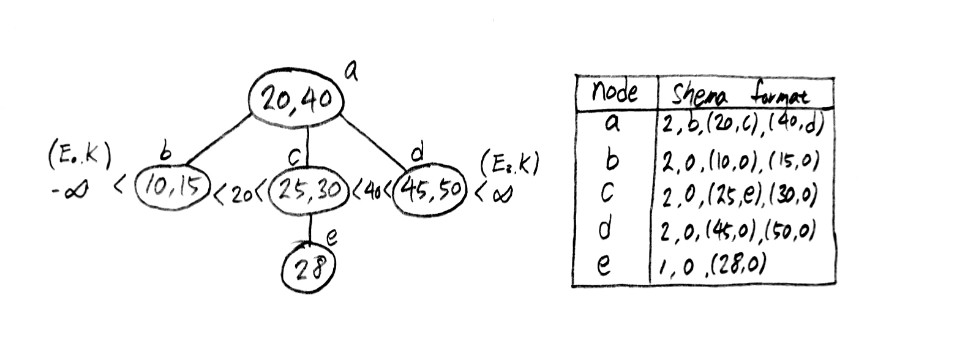
B-트리란?
B-트리는 이러한 m-원 탐색트리의 일종이며 다음과 같이 정의됩니다.
차수가 m인 B-트리의 정의

B-트리의 예시

B-트리의 삽입
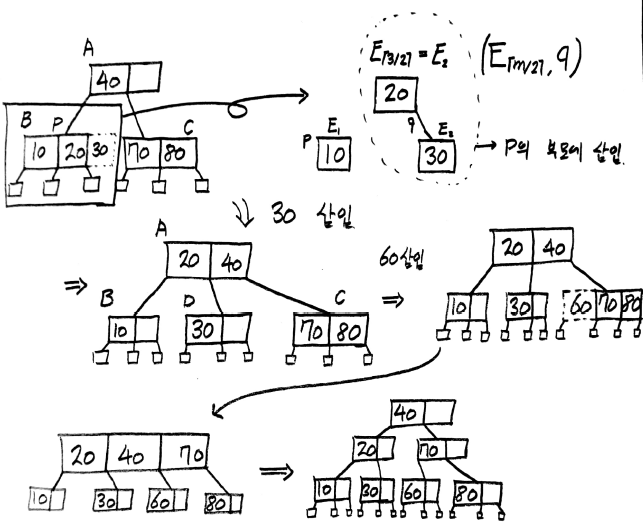
B-트리의 삭제
키가 x인 노드를 삭제하려고 할 때, x가 리프가 아닌 노드 z에서 발견될 경우, z에서 x가 차지하던 자리는 B-트리의 리프 노드로 부터 적당한 키로 채워진다. 가령 x가 그의 i번째 키라고 하면, E_i는 서브트리 A_i 내의 가장 작은 원소 혹은 서브트리 A_(i-1)의 가장 큰 원소로 채워질 수 있습니다. 여기서 삭제되는 리프노드 p에 대해 다음의 4가지 경우가 존재합니다.
CASE1
p 또한 루트노드인 경우 삭제 후 리프에 적어도 키가 하나 남아있다면 삭제 후 저장하고, 없다면 공백트리가 됩니다.
CASE2
삭제 후 p가 적어도 [m/2]-1 개의 원소를 가지고 있는 경우 즉, 최소 원소 개수가 만족되는 경우 그대로 삭제를 진행
CASE3 회전
p가 [m/2]-2개의 원소를 가지며, 인접한 형제노드 q가 적어도 [m/2]개 원소를 가지는 경우. 즉, p가 삭제 후 최소 키보다 적은 키를 가지고 있고 형제 노드는 최소 키 이상의 키를 가지고 있는 경우 다음과 같이 회전 을 진행합니다.
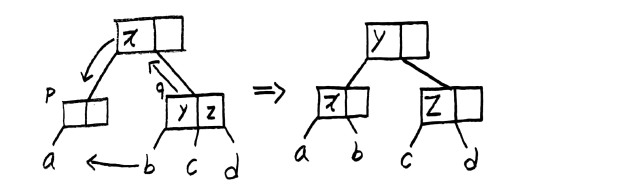
CASE4 병합
p가 [m/2]-2개의 원소를 가지고 있고, 가장 가까운 형제노드 q가 [m/2]-1개의 원소를 가지고 있는 경우. 즉, p가 삭제 후 최소 키보다 적은 키를 가지고 있고 형제 노드도 딱 최소 키만을 가지고 있는 경우 p,q와 p,q 중간 원소 E_i를 하나의 노드로 병합 합니다.
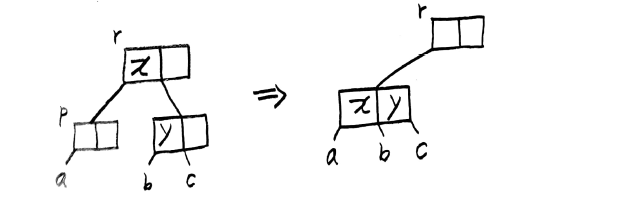
마무리
B-트리의 핵심 포인트를 정리하면:
- 목적: 디스크 I/O 횟수를 최소화하기 위해 트리 높이를 낮춘다.
- 구조: 한 노드에 여러 개의 키를 저장하고, 여러 개의 자식을 가진다.
- 균형: 항상 균형을 유지해서 최악의 경우에도 O(log n) 성능을 보장한다.
개인적인 생각: 실무에서 "인덱스를 타지 않아서 느리다"라는 말을 자주 듣는다. 이 말의 의미를 제대로 이해하려면 B-트리를 알아야 한다. 인덱스가 없으면 테이블 전체를 풀 스캔해야 하고(O(n)), 인덱스가 있으면 B-트리를 타고 O(log n)에 찾을 수 있다. 수백만 건의 데이터에서 이 차이는 엄청나다.
참고로 실제 데이터베이스에서는 B-트리보다 B+트리를 더 많이 쓴다. B+트리는 모든 데이터를 리프 노드에만 저장하고, 리프 노드끼리 링크드 리스트로 연결해서 범위 검색에 유리하다.